Arithmetic is being able to count up to twenty without taking off your shoes (Mickey Mouse)

On her last mission, Dora The Explorer sails down the Amazon river to save her friend Isa The Iguana from Swiper The Fox claws. After some hours of navigation, Dora sees how the river divides into 3 branches and has to choose which one to follow. Before leaving, her friend Map told her that just one of these branches is safe. Two others end in terrible waterfalls, both impossible to escape alive. Although Dora does not know which one is the good one, she decides to take the branch number 1. Suddenly, her friend Boots The Monkey yells from the top of a palm tree:
– Dora, do not take branch number 3! I can see from here that it ends in a horrible waterfall!
After listening to Boots, Dora changes her mind and decides to take branch number 2. Why Dora switches? Because she knows that this change has significantly increased her probability of ending the mission alive.
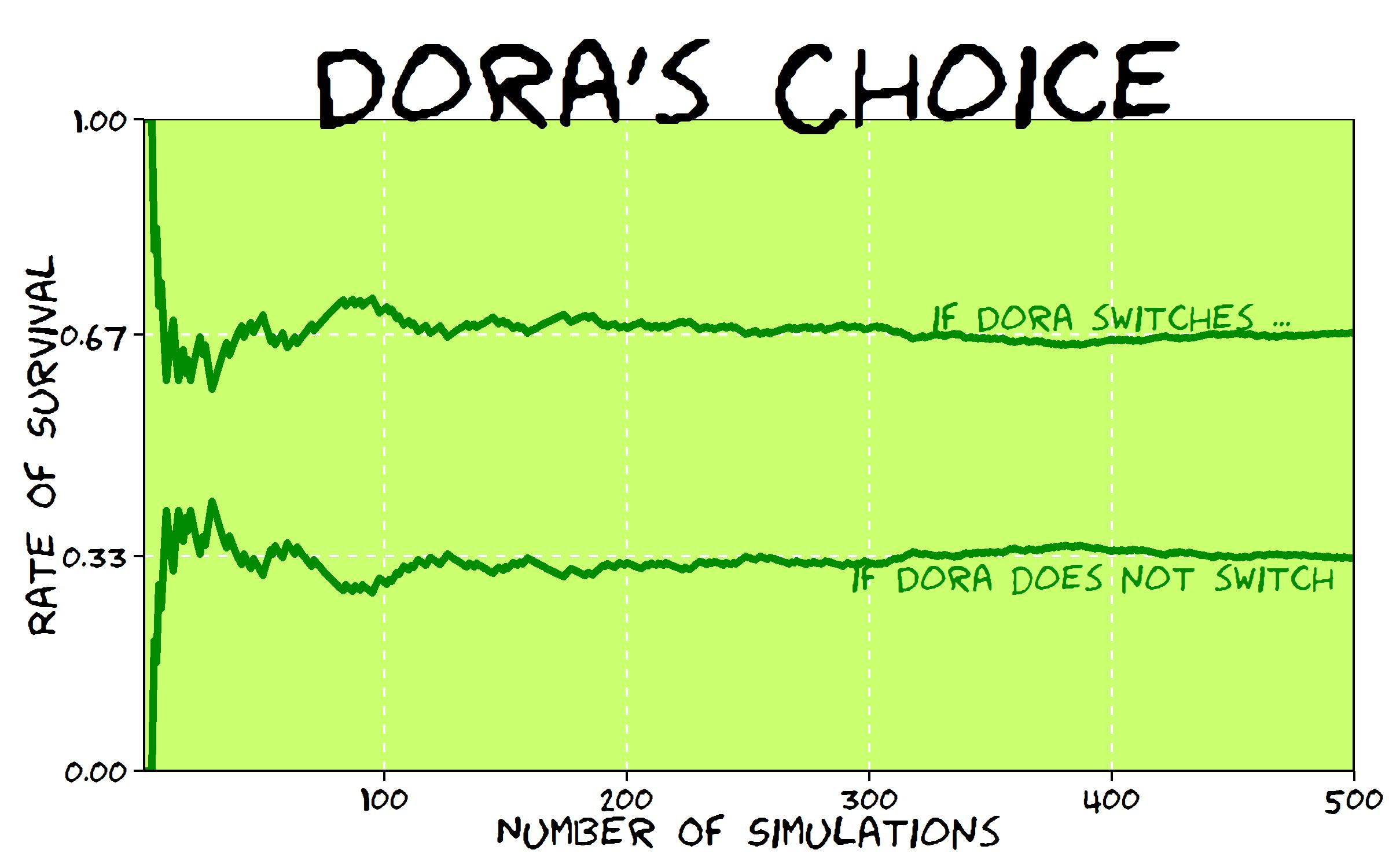
There are several ways to convince yourself of this. One is to simulate the situation that has faced Dora and compare results of switching and not switching . Switching, Dora saves her life 2 of each 3 simulations while if she does not, Dora only saves 1 of each 3 simulations. Changing her mind, Dora doubles her chances of survival!
Carefully considering what happens, you can see that switching Dora saves herself when her first choice is erroneus, which occurs with probability 2/3. On the other hand, if Dora remains faithful to her first choice, obviously only saves herself with probability 1/3.
This is an example on my own of the famous Monty Hall Problem. You can see a nice explanation of it in a chapter of Numb3rs or in the film 21 Black Jack. Not long ago I exposed the problem in a family meeting. Only my mum said she would switch (we were 6 people in the meeting). It is fun to share this experiment and ask what people would do. Do it with your friends and family. First time I knew the problem I thought there were no difference between switching and not since I gave both possibilities 1/2 of probability. If I had been Dora, pretty sure I would tumbled over a terrible waterfall. What about yo?
Note: this is an update of the post, which was not a correct formulation of Monty Hall Problem. Thanks to David Robinson and Scott Kostyshak for showing me my error. A correct formulation of the problem may be this:
On her last mission, Dora The Explorer sails down the Amazon river to meet her cousin Diego. After some hours of navigation, Dora sees how the river divides into 3 branches and has to choose which one to follow. Before leaving, her friend Map told her that just one of these branches is safe. Two others end in terrible waterfalls, both impossible to escape alive. Although Dora does not know which one is the good one, she decides to take the branch number 1. After putting the bow towards branch number one, Dora sees Swiper The Fox smiling from the shore, in a high place where obviously can see the end of all three branches. Dora yells him:
– Help me Swiper! Which one should I take?
Swiper replies:
– I am the villain of this story so I will give you only an advice: do not take branch number 3. It ends into a terrible waterfall.
Dora, who has a sixth sense to notice when Swiper is lying, knows he is telling the truth and immediately changes her mind and decides to take branch number 2. Why Dora switches? Because she knows that this change has significantly increased her probability of ending the mission alive.

Here you have the code:
library(ggplot2)
library(extrafont)
nchoices <- 3
nsims <- 500
choices <- seq(from=1, to=nchoices, by=1)
good.choice <- sample(choices, nsims, replace=TRUE)
choice1 <- sample(choices, nsims, replace=TRUE)
dfsims <- as.data.frame(cbind(good.choice, choice1))
dfsims$advice <- apply(dfsims, 1, function(x) choices[!choices %in% as.vector(x)][sample(1:length(choices[!choices %in% as.vector(x)]), 1)])
dfsims$choice2 <- apply(dfsims, 1, function(x) choices[!choices %in% as.vector(c(x[2], x[3]))][sample(1:length(choices[!choices %in% as.vector(c(x[2], x[3]))]), 1)])
dfsims$win1 <- apply(dfsims, 1, function(x) (x[1]==x[2])*1)
dfsims$win2 <- apply(dfsims, 1, function(x) (x[1]==x[4])*1)
dfsims$csumwin1 <- cumsum(dfsims$win1)/as.numeric(rownames(dfsims))
dfsims$csumwin2 <- cumsum(dfsims$win2)/as.numeric(rownames(dfsims))
dfsims$nsims <- as.numeric(rownames(dfsims))
dfsims$xaxis <- 0
### XKCD theme
theme_xkcd <- theme(
panel.background = element_rect(fill="darkolivegreen1"),
panel.border = element_rect(colour="black", fill=NA),
axis.line = element_line(size = 0.5, colour = "black"),
axis.ticks = element_line(colour="black"),
panel.grid = element_line(colour="white", linetype = 2),
axis.text.y = element_text(colour="black"),
axis.text.x = element_text(colour="black"),
text = element_text(size=18, family="Humor Sans"),
plot.title = element_text(size = 50)
)
### Plot the chart
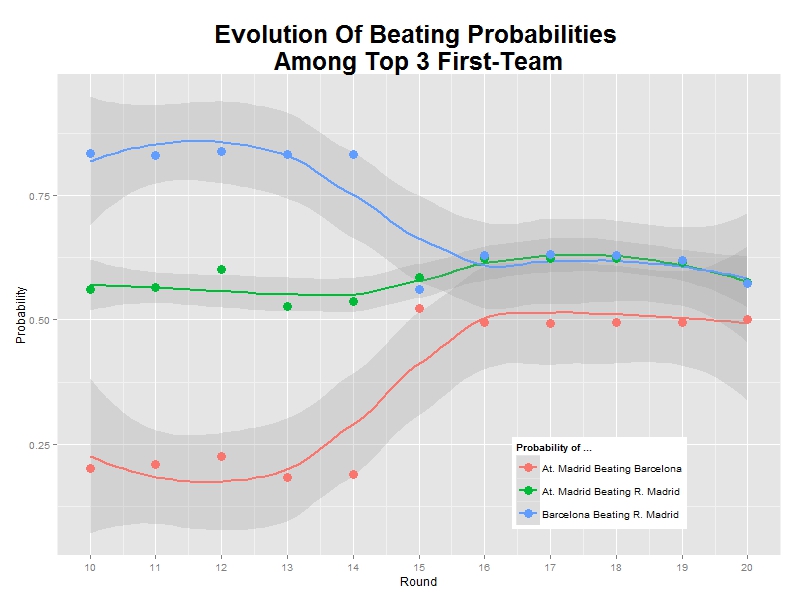
p <- ggplot(data=dfsims, aes(x=nsims, y=csumwin1))+
geom_line(aes(y=csumwin2), colour="green4", size=1.5, fill=NA)+
geom_line(colour="green4", size=1.5, fill=NA)+
geom_text(data=dfsims[400, ], family="Humor Sans", aes(x=nsims), colour="green4", y=0.7, label="if Dora switches ...", size=5.5, adjust=1)+
geom_text(data=dfsims[400, ], family="Humor Sans", aes(x=nsims), colour="green4", y=0.3, label="if Dora does not switch ...", size=5.5, adjust=1)+
coord_cartesian(ylim=c(0, 1), xlim=c(1, nsims))+
scale_y_continuous(breaks = c(0,round(1/3, digits = 2),round(2/3, digits = 2),1), minor_breaks = c(round(1/3, digits = 2),round(2/3, digits = 2)))+
scale_x_continuous(minor_breaks = seq(100, 400, 100))+
labs(x="Number Of Simulations", y="Rate Of Survival", title="Dora's Choice")+
theme_xkcd
ggsave("doras_choice.jpg", plot=p, width=8, height=5)
 Another chance? told me Mr. Penney. Of course! Now my bet is TTH! I said. In fact, I was thinking Take that! Now I chose your previous bet. Do you think I am foolish?. After some seconds, Mr. Penney said: My bet now is HTT.
Another chance? told me Mr. Penney. Of course! Now my bet is TTH! I said. In fact, I was thinking Take that! Now I chose your previous bet. Do you think I am foolish?. After some seconds, Mr. Penney said: My bet now is HTT.
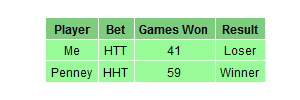 Ok, I give it up! What’s the trick? I said. And Mr. Penney explained it to me. You can find the explanation here. This is the last time I play with you! I told him once he finished the explanation.
Ok, I give it up! What’s the trick? I said. And Mr. Penney explained it to me. You can find the explanation here. This is the last time I play with you! I told him once he finished the explanation.