Spinning on that dizzy edge (Just Like Heaven, The Cure)
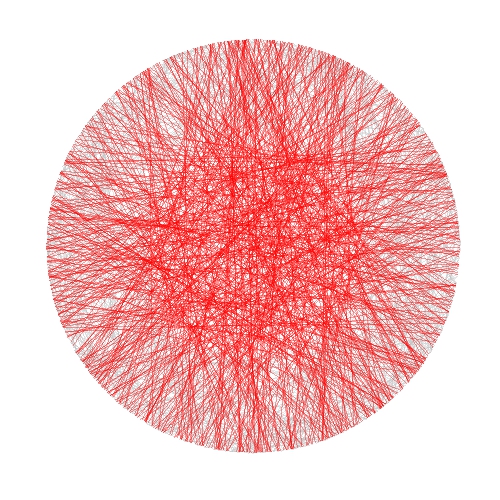
This post talks about a generative system called Physarum model, which simulates the evolution of a colony of extremely simple organisms that, under certain environmental conditions, result into complex behaviors. Apart from the scientific interest of the topic, this model produce impressive images like this one, that I call The Death of a Red Dwarf:

You can find a clear explanation of how a physarum model works in this post, by Sage Jenson. A much deeper explanation can be found in this paper by Jeff Jones, from the University of the West of England. Briefly, a physarum model evolves a set of particles (agents), making them move over a surface. Agents turn towards locations with higher concentrations of a pheromone trail. Once they move, they make a deposition of pheromone as well. These are the steps of a single iteration of the model:
- Sensor stage: Each agent looks to three positions of the trail map (left, front and right) according a certain sensor angle
- Motor stage: then it moves to the place with the higher concentration with some rules to deal with ties
- Deposition stage: once in the new location, the agent deposites a certain amount of pheromone.
- Diffuse stage: the pheromones diffusing over the surface to blur the trail array.
- Decay stage: this make to decay the concentration of pheromone on the surface.
Sage Jenson explains the process with this illustrative diagram:

My implementation is a bit different from Jones’ one. The main difference is that I do not apply the diffuse stage after deposition: I prefer a high defined picture instead blurriyng it. I also play with the initial arrangement of agents (location and heading angle) as well with the initial configuration of environment. For example, In The Death of a Red Dwarf, agents start from a circle and the environment is initialized in a dense disc. You can find the details in the code. There you will see that the system is governed by the following parameters:
- Front and left sensor angles from forward position
- Agent rotation angle
- Sensor offset distance
- Step size (how far agent moves per step)
- Chemoattractant deposition per step
- Trail-map chemoattractant diffusion decay factor
In adition to them (specific of the physarum model), you also can change others like colors, noise of angles (parameter amount of jitter function), number of agents and iterations as well as the initial arrangement of the environment and the location of agents. I invite you to do it. You will discover many abstractions: butterfly wings, planets, nets, explosions, supernovas … I have spent may hours playing with it. Some examples:









You can find the code here. Please, let me know if you do something interesting with it. Share your artworks with me in Twitter or drop me an email (you can find my address here).




























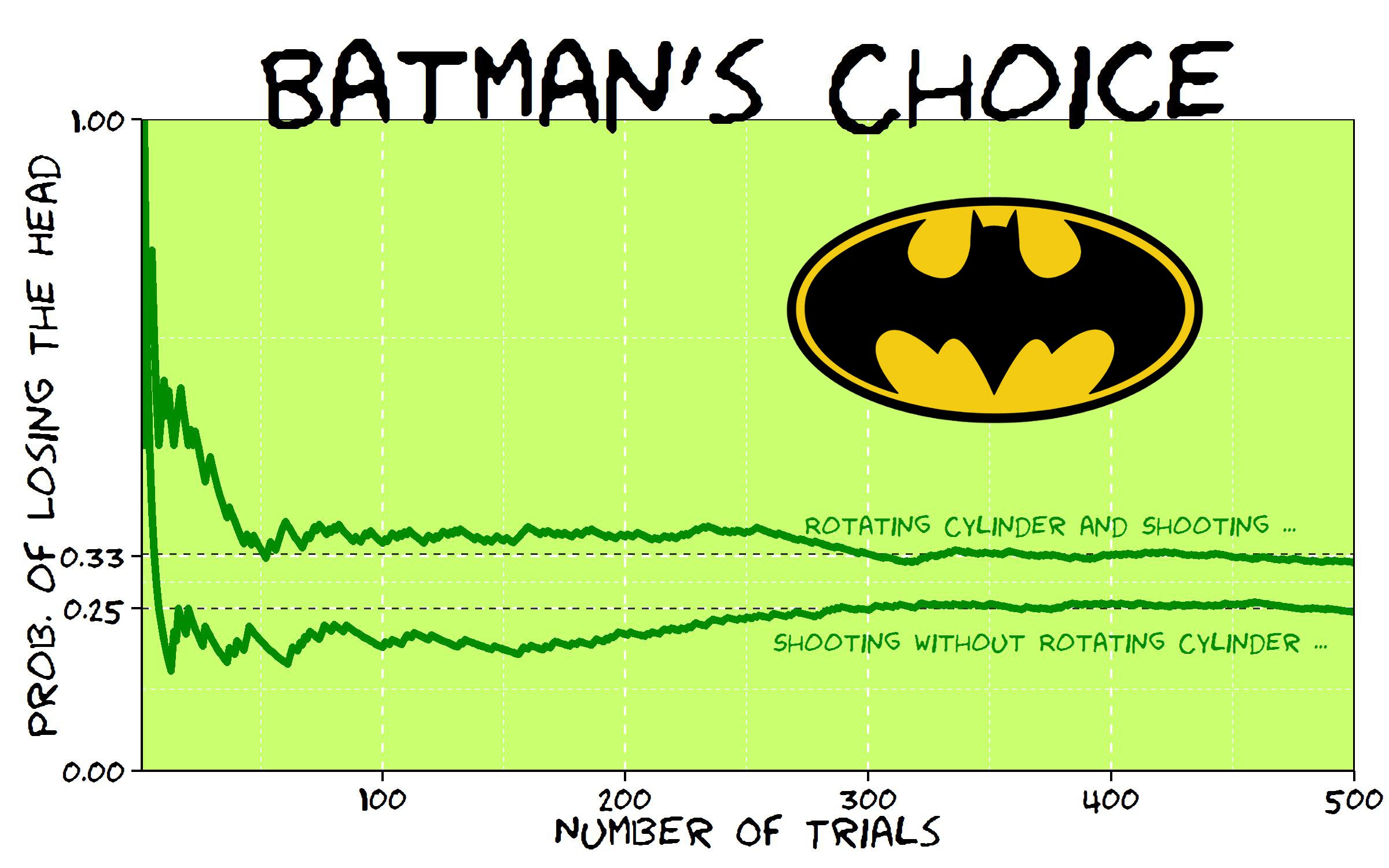
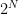 possible outcomes and only
possible outcomes and only  are favorable so the exact probability is the quotient of these numbers (# of favorable divided by # of possible).
are favorable so the exact probability is the quotient of these numbers (# of favorable divided by # of possible).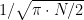
 in the most unexpected places, as happens
in the most unexpected places, as happens