I am an absolute beginner, but I am absolutely sane (Absolute Beginners, David Bowie)
Some time ago I wrote this post, where I predicted correctly the winner of the Spanish Football League several months before its ending. After thinking intensely about taking the risk of ruining my reputation repeating the analysis, I said “no problem, Antonio, do it again: in the end you don’t have any reputation to keep”. So here we are.
From a technical point of view there are many differences between both analysis. Now I use webscraping to download data, dplyr and pipes to do transformations and interactive D3.js graphs to show results. I think my code is better now and it makes me happy.
As I did the other time, Bradley-Terry Model gives an indicator of the power of each team, called ability, which provides a natural mechanism for ranking teams. This is the evolution of abilities of each team during the championship (last season was played during the past weekend):

Although it is a bit messy, the graph shows two main groups of teams: on the one hand, Barcelona, Atletico de Madrid, Real Madrid and Villareal; on the other hand, the rest. Let’s have a closer look to evolution of the abilities of the top 4 teams:

While Barcelona, Atletico de Madrid and Real Madrid walk in parallel, Villareal seems to be a bit stacked in the last seasons; the gap between them and Real Madrid is increasing little by little. Maybe is the Zidane’s effect. It is quite interesting discovering what teams are increasing their abilities: they are Malaga, Eibar and Getafe. They will probably finish the championship in a better position than they have nowadays (Eibar could reach fifth position):

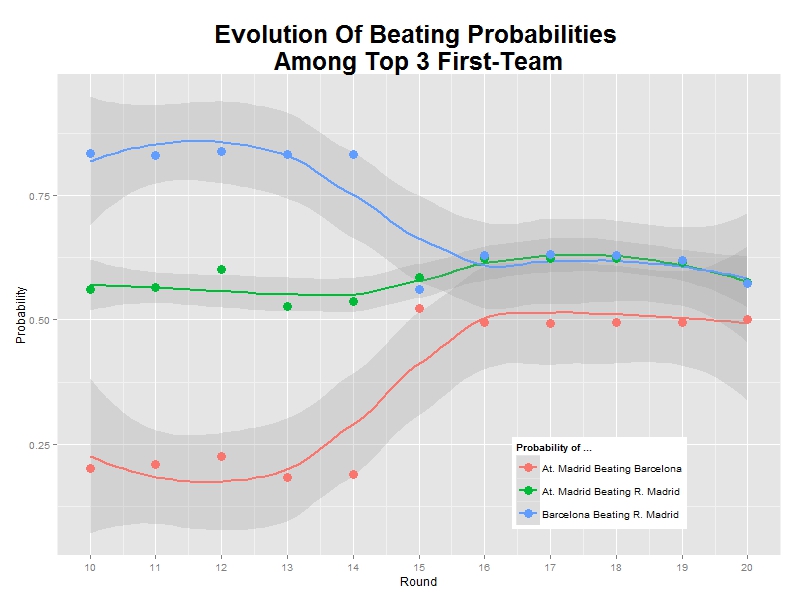
What about Villareal? Will they go up some position? I don’t think so. This plot shows the probability of winning any of the top 3:

As you can see, probability is decreasing significantly. And what about Barcelona? Will win? It is a very difficult question. They are almost tied with Atletico de Madrid, and only 5 and 8 points above Real Madrid and Villareal. But it seems Barcelona keep them at bay. This plot shows the evolution of the probability of be beaten by Atletico, Real Madrid and Villareal:

All probabilities are under 50% and decreasing (I supposed a scoring of 2-0 for Barcelona in the match against Sporting of season 16 that was postponed to next February 17th).
Data science is a profession for brave people so it is time to do some predictions. These are mine, ordered by likelihood:
- Barcelona will win, followed by Atletico (2), Real Madrid (3), Villareal (4) and Eibar (5)
- Malaga and Getafe will go up some positions
- Next year I will do the analysis again
Here you have the code:
library(rvest)
library(stringr)
library(BradleyTerry2)
library(dplyr)
library(reshape)
library(rCharts)
nseasons=20
results=data.frame()
for (i in 1:nseasons)
{
webpage=paste0("http://www.marca.com/estadisticas/futbol/primera/2015_16/jornada_",i,"/")
html(webpage) %>%
html_nodes("table") %>%
.[[1]] %>%
html_table(header=FALSE, fill=TRUE) %>%
mutate(X4=i) %>%
rbind(results)->results
}
colnames(results)=c("home", "score", "visiting", "season")
results %>%
mutate(home = iconv(home, from="UTF8",to="ASCII//TRANSLIT"),
visiting = iconv(visiting, from="UTF8",to="ASCII//TRANSLIT")) %>%
#filter(grepl("-", score)) %>%
mutate(score=replace(score, score=="18:30 - 17/02/2016", "0-2")) %>% # resultado fake para el Barcelona
mutate(score_home = as.numeric(str_split_fixed(score, "-", 2)[,1])) %>%
mutate(score_visiting = as.numeric(str_split_fixed(score, "-", 2)[,2])) %>%
mutate(points_home =ifelse(score_home > score_visiting, 3, ifelse(score_home < score_visiting, 0, 1))) %>%
mutate(points_visiting =ifelse(score_home > score_visiting, 0, ifelse(score_home < score_visiting, 3, 1))) -> data
prob_BT=function(x, y) {exp(x-y) / (1 + exp(x-y))}
BTabilities=data.frame()
for (i in 13:nseasons)
{
data %>% filter(season<=i) %>%
BTm(cbind(points_home, points_visiting), home, visiting, data=.) -> footballBTModel
BTabilities(footballBTModel) %>%
as.data.frame() -> tmp
cbind(tmp, as.character(rownames(tmp)), i) %>%
mutate(ability=round(ability, digits = 2)) %>%
rbind(BTabilities) -> BTabilities
}
colnames(BTabilities)=c("ability", "s.e.", "team", "season")
sort(unique(BTabilities[,"team"])) -> teams
BTprobabilities=data.frame()
for (i in 13:nseasons)
{
BTabilities[BTabilities$season==i,1] %>% outer( ., ., prob_BT) -> tmp
colnames(tmp)=teams
rownames(tmp)=teams
cbind(melt(tmp),i) %>% rbind(BTprobabilities) -> BTprobabilities
}
colnames(BTprobabilities)=c("team1", "team2", "probability", "season")
BTprobabilities %>%
filter(team1=="Villarreal") %>%
mutate(probability=round(probability, digits = 2)) %>%
filter(team2 %in% c("R. Madrid", "Barcelona", "Atletico")) -> BTVillareal
BTprobabilities %>%
filter(team2=="Barcelona") %>%
mutate(probability=round(probability, digits = 2)) %>%
filter(team1 %in% c("R. Madrid", "Villarreal", "Atletico")) -> BTBarcelona
AbilityPlot <- nPlot(
ability ~ season,
data = BTabilities,
group = "team",
type = "lineChart")
AbilityPlot$yAxis(axisLabel = "Estimated Ability", width = 62)
AbilityPlot$xAxis(axisLabel = "Season")
VillarealPlot <- nPlot(
probability ~ season,
data = BTVillareal,
group = "team2",
type = "lineChart")
VillarealPlot$yAxis(axisLabel = "Probability of beating", width = 62)
VillarealPlot$xAxis(axisLabel = "Season")
BarcelonaPlot <- nPlot(
probability ~ season,
data = BTBarcelona,
group = "team1",
type = "lineChart")
BarcelonaPlot$yAxis(axisLabel = "Probability of being beaten", width = 62)
BarcelonaPlot$xAxis(axisLabel = "Season")