If I keep holding out, will the light shine through? (Come Back, Pearl Jam)
Imagine that you are writing the story of your life. Almost sure you will make allusions to your parents, but will both of them have the same prominence in your biography or will you spend more words in one of them? In that case, which one will have more relevance? Your father or your mother?
This experiment analyses 118 autobiographies from the Project Gutenberg and count how many times do authors make allusions to their fathers and mothers. This is what I’ve done:
- Download all works from Gutenberg Project containing the word autobiography in its title (there are 118 in total).
- Count how many times the bigrams my father and my mother appear in each text. This is what I call allusions to father and mother respectively.
The number of allusions that I measure is a lower bound of the exact amount of them since the calculus has some limitations:
- Maybe the author refers to them by their names.
- After referring to them as my father or my mother, subsequent sentences may refer them as He or She.
Anyway, I think these constrains do not introduce any bias in the calculus since may affect to fathers and mothers equally. Here you can find the dataset I created after downloading all autobiographies and measuring the number of allusions to each parent.
Some results:
- 64% of autobiographies have more allusions to the father than the mother.
- 24% of autobiographies have more allusions to the mother than the father.
- 12% allude them equally.
Most of the works make more allusions to father than to mother. As a visual proof of this fact, the next plot is a histogram of the difference between the amount of allusions to father and mother along the 118 works (# allusions to father – # allusions to mother):

The distribution is clearly right skeweed, which supports our previous results. Another way to see this fact is this last plot, which situates each autobiography in a scatter plot, where X-axis is the amount of allusions to father and Y-axis to mother. It is interactive, so you can navigate through it to see the details of each point (work):
Most of the points (works) are below the diagonal, which means that they contain more allusions to father than mother. Here you can find a full version of the previous plot.
I don’t have any explanation to this fact, just some simple hypothesis:
- Fathers and mothers influence their children differently.
- Fathers star in more anecdotes than mothers.
- This is the effect of patriarchy (72% of authors was born in the XIX century)
Whatever it is the explanation, this experiment shows how easy is to do text mining with R. Special mention to purrr (to iterate eficiently over the set of works IDs), tidytext (to count the number of appearances of bigrams), highcharter (to do the interactive plot) and gutenbergr (to download the books). You can find the code here.


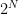 possible outcomes and only
possible outcomes and only  are favorable so the exact probability is the quotient of these numbers (# of favorable divided by # of possible).
are favorable so the exact probability is the quotient of these numbers (# of favorable divided by # of possible).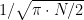
 in the most unexpected places, as happens
in the most unexpected places, as happens