It seemed that everything is in ruins, and that all the basic mathematical concepts have lost their meaning (Naum Vilenkin, Russian mathematician, regarding to the discovery of Peano’s curve)
Giuseppe Peano found in 1890 a way to draw a curve in the plane that filled the entire space: just a simple line covering completely a two dimensional plane. Its discovery meant a big earthquake in the traditional structure of mathematics. Peano’s curve was the first but not the last: one of these space-filling curves was discovered by Hilbert and takes his name. It is really beautiful:

Hilbert’s curve can be created iteratively. These are the first six iterations of its construction:

As you will see below, R code to create Hilbert’s curve is extremely easy. It is also very easy to play with the curve, altering the order in which points are sorted. Changing the initial matrix(1) by some other number, resulting curves are quite appealing:
Let’s go futher. Changing ggplot geometry from geom_path to geom_polygon generate some crazy pseudo-tessellations:
And what if you change the matrix exponent?
And what if you apply polar coordinates?
We started with a simple line and with some small changes we have created fantastical images. And all these things only using black and white. Do you want to add some colors? Try with the following code (if you draw something interesting, please let me know):
library(reshape2)
library(dplyr)
library(ggplot2)
opt=theme(legend.position="none",
panel.background = element_rect(fill="white"),
panel.grid=element_blank(),
axis.ticks=element_blank(),
axis.title=element_blank(),
axis.text=element_blank())
hilbert = function(m,n,r) {
for (i in 1:n)
{
tmp=cbind(t(m), m+nrow(m)^2)
m=rbind(tmp, (2*nrow(m))^r-tmp[nrow(m):1,]+1)
}
melt(m) %>% plyr::rename(c("Var1" = "x", "Var2" = "y", "value"="order")) %>% arrange(order)}
# Original
ggplot(hilbert(m=matrix(1), n=1, r=2), aes(x, y)) + geom_path()+ opt
ggplot(hilbert(m=matrix(1), n=2, r=2), aes(x, y)) + geom_path()+ opt
ggplot(hilbert(m=matrix(1), n=3, r=2), aes(x, y)) + geom_path()+ opt
ggplot(hilbert(m=matrix(1), n=4, r=2), aes(x, y)) + geom_path()+ opt
ggplot(hilbert(m=matrix(1), n=5, r=2), aes(x, y)) + geom_path()+ opt
ggplot(hilbert(m=matrix(1), n=6, r=2), aes(x, y)) + geom_path()+ opt
# Changing order
ggplot(hilbert(m=matrix(.5), n=5, r=2), aes(x, y)) + geom_path()+ opt
ggplot(hilbert(m=matrix(0), n=5, r=2), aes(x, y)) + geom_path()+ opt
ggplot(hilbert(m=matrix(tan(1)), n=5, r=2), aes(x, y)) + geom_path()+ opt
ggplot(hilbert(m=matrix(3), n=5, r=2), aes(x, y)) + geom_path()+ opt
ggplot(hilbert(m=matrix(-1), n=5, r=2), aes(x, y)) + geom_path()+ opt
ggplot(hilbert(m=matrix(log(.1)), n=5, r=2), aes(x, y)) + geom_path()+ opt
ggplot(hilbert(m=matrix(-15), n=5, r=2), aes(x, y)) + geom_path()+ opt
ggplot(hilbert(m=matrix(-0.001), n=5, r=2), aes(x, y)) + geom_path()+ opt
# Polygons
ggplot(hilbert(m=matrix(log(1)), n=4, r=2), aes(x, y)) + geom_polygon()+ opt
ggplot(hilbert(m=matrix(.5), n=4, r=2), aes(x, y)) + geom_polygon()+ opt
ggplot(hilbert(m=matrix(tan(1)), n=5, r=2), aes(x, y)) + geom_polygon()+ opt
ggplot(hilbert(m=matrix(-15), n=4, r=2), aes(x, y)) + geom_polygon()+ opt
ggplot(hilbert(m=matrix(-25), n=4, r=2), aes(x, y)) + geom_polygon()+ opt
ggplot(hilbert(m=matrix(0), n=4, r=2), aes(x, y)) + geom_polygon()+ opt
ggplot(hilbert(m=matrix(1000000), n=4, r=2), aes(x, y)) + geom_polygon()+ opt
ggplot(hilbert(m=matrix(-1), n=4, r=2), aes(x, y)) + geom_polygon()+ opt
ggplot(hilbert(m=matrix(-.00001), n=4, r=2), aes(x, y)) + geom_polygon()+ opt
# Changing exponent
gplot(hilbert(m=matrix(log(1)), n=4, r=-1), aes(x, y)) + geom_polygon()+ opt
ggplot(hilbert(m=matrix(.5), n=4, r=-2), aes(x, y)) + geom_polygon()+ opt
ggplot(hilbert(m=matrix(tan(1)), n=4, r=6), aes(x, y)) + geom_polygon()+ opt
ggplot(hilbert(m=matrix(-15), n=3, r=sin(2)), aes(x, y)) + geom_polygon()+ opt
ggplot(hilbert(m=matrix(-25), n=4, r=-.0001), aes(x, y)) + geom_polygon()+ opt
ggplot(hilbert(m=matrix(0), n=4, r=200), aes(x, y)) + geom_polygon()+ opt
ggplot(hilbert(m=matrix(1000000), n=3, r=.5), aes(x, y)) + geom_polygon()+ opt
ggplot(hilbert(m=matrix(-1), n=4, r=sqrt(2)), aes(x, y)) + geom_polygon()+ opt
ggplot(hilbert(m=matrix(-.00001), n=4, r=52), aes(x, y)) + geom_polygon()+ opt
# Polar coordinates
ggplot(hilbert(m=matrix(1), n=4, r=2), aes(x, y)) + geom_polygon()+ coord_polar()+opt
ggplot(hilbert(m=matrix(-1), n=5, r=2), aes(x, y)) + geom_polygon()+ coord_polar()+opt
ggplot(hilbert(m=matrix(.1), n=2, r=.5), aes(x, y)) + geom_polygon()+ coord_polar()+opt
ggplot(hilbert(m=matrix(1000000), n=2, r=.1), aes(x, y)) + geom_polygon()+ coord_polar()+opt
ggplot(hilbert(m=matrix(.25), n=3, r=3), aes(x, y)) + geom_polygon()+ coord_polar()+opt
ggplot(hilbert(m=matrix(tan(1)), n=5, r=1), aes(x, y)) + geom_polygon()+ coord_polar()+opt
ggplot(hilbert(m=matrix(1), n=4, r=1), aes(x, y)) + geom_polygon()+ coord_polar()+opt
ggplot(hilbert(m=matrix(log(1)), n=3, r=sin(2)), aes(x, y)) + geom_polygon()+ coord_polar()+opt
ggplot(hilbert(m=matrix(-.0001), n=4, r=25), aes(x, y)) + geom_polygon()+ coord_polar()+opt

 Dark green vertex are those labeled with prime numbers and light ones with non-prime. This is the sixth iteration colored as I described before (I removed lines and labels):
Dark green vertex are those labeled with prime numbers and light ones with non-prime. This is the sixth iteration colored as I described before (I removed lines and labels):























































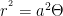
 is the radius,
is the radius, 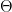 is the polar angle and
is the polar angle and  is simply a compress constant.
is simply a compress constant.




