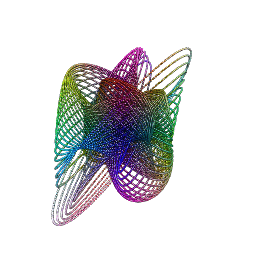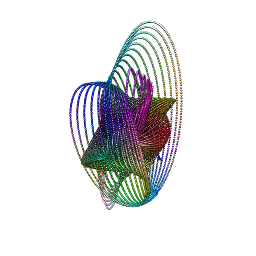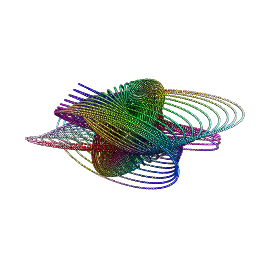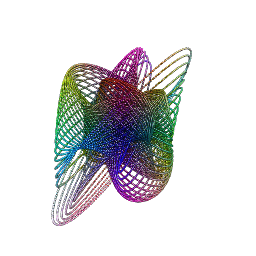She makes the sound the sea makes to calm me down (Dissolve Me, Alt-J)
Searching how to do draw chord diagrams in the Internet with ggplot2 I found a very-easy-to-use package called circlize which does exactly that. A chord diagram shows relationships between things so the input to draw it is simply a matrix with the intensity of these relations. In this experiment I use this package to circlize numbers in this way:
- I take a number with many digits (
Rmpfrpackage is very useful to obtain large numbers), I convert it to text and remove punctuation characters (necessary if number has decimals) - Function
CreateAdjacencyMatrixcreates a 10×10 matrix where the element [i,j] contains the number of times that number “i” precedes to number “j” in the previous string (i and j from 0 to 9); this is the input to create diagram.
These diagrams are the result of circlizing four famous constants: Pi (green), Gamma (purple), Catalan (blue) and Logarithm constants (red):

Just two conclusions of my own to end:
- Circlize package is very easy to use and generates very nice diagrams
- Chord diagrams remember me to dreamcatchers
- The more I use
RColorBrewerpackage the more I like it
This is the code to circlize numbers:
library(Rmpfr)
library(circlize)
library(RColorBrewer)
CreateAdjacencyMatrix = function(x) {
s=gsub("\\.", "", x)
m=matrix(0, 10, 10)
for (i in 1:(nchar(s)-1)) m[as.numeric(substr(s, i, i))+1, as.numeric(substr(s, i+1, i+1))+1]=m[as.numeric(substr(s, i, i))+1, as.numeric(substr(s, i+1, i+1))+1]+1
rownames(m) = 0:9;colnames(m) = 0:9
m}
m1=CreateAdjacencyMatrix(formatMpfr(Const("pi",2000)))
m2=CreateAdjacencyMatrix(formatMpfr(Const("gamma",2000)))
m3=CreateAdjacencyMatrix(formatMpfr(Const("catalan",2000)))
m4=CreateAdjacencyMatrix(formatMpfr(Const("log2",2000)))
jpeg(filename = "Chords.jpg", width = 800, height = 800, quality = 100)
par(mfrow=c(2,2), mar = c(1, 1, 1, 1))
chordDiagram(m1, grid.col = "darkgreen",
col = colorRamp2(quantile(m1, seq(0, 1, by = 0.25)), brewer.pal(5,"Greens")),
transparency = 0.4, annotationTrack = c("name", "grid"))
chordDiagram(m2, grid.col = "mediumpurple4",
col = colorRamp2(quantile(m2, seq(0, 1, by = 0.25)), brewer.pal(5,"Purples")),
transparency = 0.4, annotationTrack = c("name", "grid"))
chordDiagram(m3, grid.col = "midnightblue",
col = colorRamp2(quantile(m3, seq(0, 1, by = 0.25)), brewer.pal(5,"Blues")),
transparency = 0.4, annotationTrack = c("name", "grid"))
chordDiagram(m4, grid.col = "red3",
col = colorRamp2(quantile(m4, seq(0, 1, by = 0.25)), brewer.pal(5,"Reds")),
transparency = 0.4, annotationTrack = c("name", "grid"))
dev.off()