I believe in the truth of fairy-tales more than I believe in the truth in the newspaper (Lotte Reiniger)
In my opinion, this graph is a visual demonstration that we live in a male chauvinist world.

In this experiment I download the members of ten top orchestras of the world with the amazing rvest package. After cleaning texts, I obtain the gender of names with genderizeR package as I did here. Since I only take into account names genderized with high probability, these numbers cannot be exact. Apart of this, the plot speaks by itself.
setwd("YOUR WORKING DIRECTORY HERE")
library(rvest)
library(dplyr)
library(genderizeR)
read_html("http://www.berliner-philharmoniker.de/en/orchestra/") %>%
html_nodes(".name") %>%
html_text(trim=TRUE) %>%
iconv("UTF-8") %>%
gsub("[\r,\n]"," ", .) %>%
gsub("\\s+", " ", .) %>%
paste(collapse=" ") %>%
findGivenNames() -> berliner
saveRDS(berliner, file="berliner.RDS")
read_html("https://www.concertgebouworkest.nl/en/musicians") %>%
html_nodes(".u-padding--b2") %>%
html_text(trim=TRUE) %>%
iconv("UTF-8") %>%
gsub("\\s+", " ", .) %>%
paste(collapse=" ") %>%
findGivenNames() -> rco
saveRDS(rco, file="rco.RDS")
read_html("http://www.philharmonia.spb.ru/en/about/orchestra/zkrasof/contents/") %>%
html_nodes(".td") %>%
html_text(trim=TRUE) %>%
iconv("UTF-8") %>%
gsub("[\r,\n]"," ", .) %>%
gsub("\\s+", " ", .) %>%
.[23] %>%
findGivenNames() -> spb
saveRDS(spb, file="spb.RDS")
read_html("http://ocne.mcu.es/conoce-a-la-ocne/orquesta-nacional-de-espana/componentes/") %>%
html_nodes(".col-main") %>%
html_text(trim=TRUE) %>%
iconv("UTF-8") %>%
gsub("[\r,\n]"," ", .) %>%
gsub("\\s+", " ", .) %>%
gsub("([[:lower:]])([[:upper:]][[:lower:]])", "\\1 \\2", .) %>%
findGivenNames() -> one
saveRDS(one, file="one.RDS")
read_html("http://www.gewandhausorchester.de/en/orchester/") %>%
html_nodes("#content") %>%
html_text(trim=TRUE) %>%
iconv("UTF-8") %>%
gsub("[\r,\n]"," ", .) %>%
gsub("\\s+", " ", .) %>%
findGivenNames() -> leipzig
saveRDS(leipzig, file="leipzig.RDS")
read_html("http://www.wienerphilharmoniker.at/orchestra/members") %>%
html_nodes(".ModSuiteMembersC") %>%
html_text(trim=TRUE) %>%
iconv("UTF-8") %>%
gsub("[\r,\n,\t,*]"," ", .) %>%
gsub("\\s+", " ", .) %>%
gsub("([[:lower:]])([[:upper:]][[:lower:]])", "\\1 \\2", .) %>%
paste(collapse=" ") %>%
.[-18] %>%
findGivenNames() -> wiener
saveRDS(wiener, file="wiener.RDS")
read_html("http://www.laphil.com/philpedia/orchestra-roster") %>%
html_nodes(".view-content") %>%
html_text(trim=TRUE) %>%
iconv("UTF-8") %>%
gsub("\\s+", " ", .) %>%
gsub("(?%
.[1] %>%
findGivenNames() -> laphil
saveRDS(laphil, file="laphil.RDS")
read_html("http://nyphil.org/about-us/meet/musicians-of-the-orchestra") %>%
html_nodes(".resp-tab-content-active") %>%
html_text(trim=TRUE) %>%
iconv("UTF-8") %>%
gsub("[\r,\n]"," ", .) %>%
gsub("\\s+", " ", .) %>%
gsub("(?%
findGivenNames() -> nyphil
saveRDS(nyphil, file="nyphil.RDS")
urls=c("http://lso.co.uk/orchestra/players/strings.html",
"http://lso.co.uk/orchestra/players/woodwind.html",
"http://lso.co.uk/orchestra/players/brass.html",
"http://lso.co.uk/orchestra/players/percussion-harps-and-keyboards.html")
sapply(urls, function(x)
{
read_html(x) %>%
html_nodes(".clearfix") %>%
html_text(trim=TRUE) %>%
iconv("UTF-8") %>%
gsub("[\r,\n,\t,*]"," ", .) %>%
gsub("\\s+", " ", .)
}) %>% paste(., collapse=" ") %>%
findGivenNames() -> lso
saveRDS(lso, file="lso.RDS")
read_html("http://www.osm.ca/en/discover-osm/orchestra/musicians-osm") %>%
html_nodes("#content-column") %>%
html_text(trim=TRUE) %>%
iconv("UTF-8") %>%
gsub("[\r,\n]"," ", .) %>%
gsub("\\s+", " ", .) %>%
findGivenNames() -> osm
saveRDS(osm, file="osm.RDS")
rbind(c("berliner", "Berliner Philharmoniker"),
c("rco", "Royal Concertgebouw Amsterdam"),
c("spb", "St. Petersburg Philharmonic Orchestra"),
c("one", "Orquesta Nacional de España"),
c("leipzig", "Gewandhaus Orchester Leipzig"),
c("wiener", "Wiener Philarmoniker"),
c("laphil", "The Los Angeles Philarmonic"),
c("nyphil", "New York Philarmonic"),
c("lso", "London Symphony Orchestra"),
c("osm", "Orchestre Symphonique de Montreal")) %>% as.data.frame()-> Orchestras
colnames(Orchestras)=c("Id", "Orchestra")
list.files(getwd(),pattern = ".RDS") %>%
lapply(function(x)
readRDS(x) %>% as.data.frame(stringsAsFactors = FALSE) %>% cbind(Id=gsub(".RDS", "", x))
) %>% do.call("rbind", .) -> all
all %>% mutate(probability=as.numeric(probability)) %>%
filter(probability > 0.9 & count > 15) %>%
filter(!name %in% c("viola", "tuba", "harp")) %>%
group_by(Id, gender) %>%
summarize(Total=n())->all
all %>% filter(gender=="female") %>% mutate(females=Total) %>% select(Id, females) -> females
all %>% group_by(Id) %>% summarise(Total=sum(Total)) -> total
inner_join(total, females, by = "Id") %>% mutate(po_females=females/Total) %>%
inner_join(Orchestras, by="Id")-> df
library(ggplot2)
library(scales)
opts=theme(legend.position="none",
plot.background = element_rect(fill="gray85"),
panel.background = element_rect(fill="gray85"),
panel.grid.major.y=element_blank(),
panel.grid.major.x=element_line(colour="white", size=2),
panel.grid.minor=element_blank(),
axis.title = element_blank(),
axis.line.y = element_line(size = 2, color="black"),
axis.text = element_text(colour="black", size=18),
axis.ticks=element_blank(),
plot.title = element_text(size = 35, face="bold", margin=margin(10,0,10,0), hjust=0))
ggplot(df, aes(reorder(Orchestra, po_females), po_females)) +
geom_bar(stat="identity", fill="darkviolet", width=.5)+
scale_y_continuous(labels = percent, expand = c(0, 0), limits=c(0,.52))+
geom_text(aes(label=sprintf("%1.0f%%", 100*po_females)), hjust=-0.05, size=6)+
ggtitle(expression(atop(bold("Women in Orchestras"), atop("% of women among members", "")))) +
coord_flip()+opts










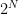 possible outcomes and only
possible outcomes and only  are favorable so the exact probability is the quotient of these numbers (# of favorable divided by # of possible).
are favorable so the exact probability is the quotient of these numbers (# of favorable divided by # of possible).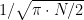
 in the most unexpected places, as happens
in the most unexpected places, as happens