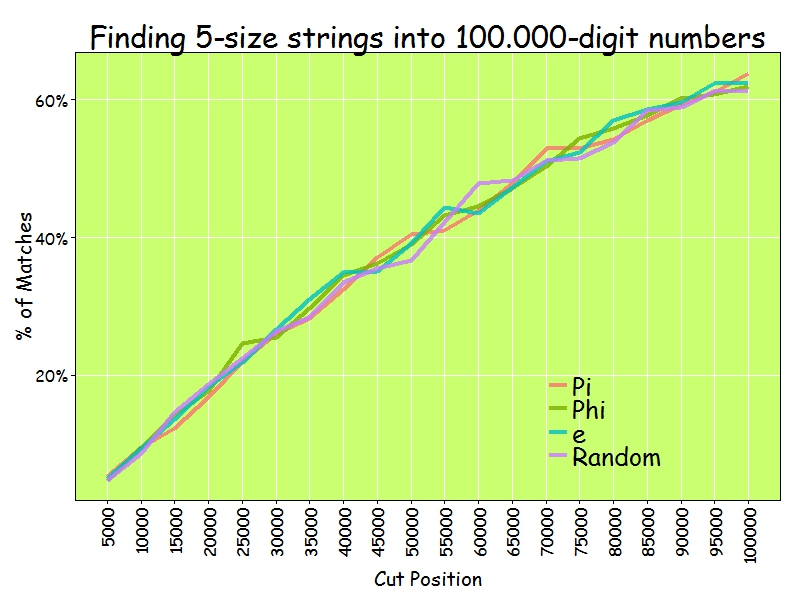
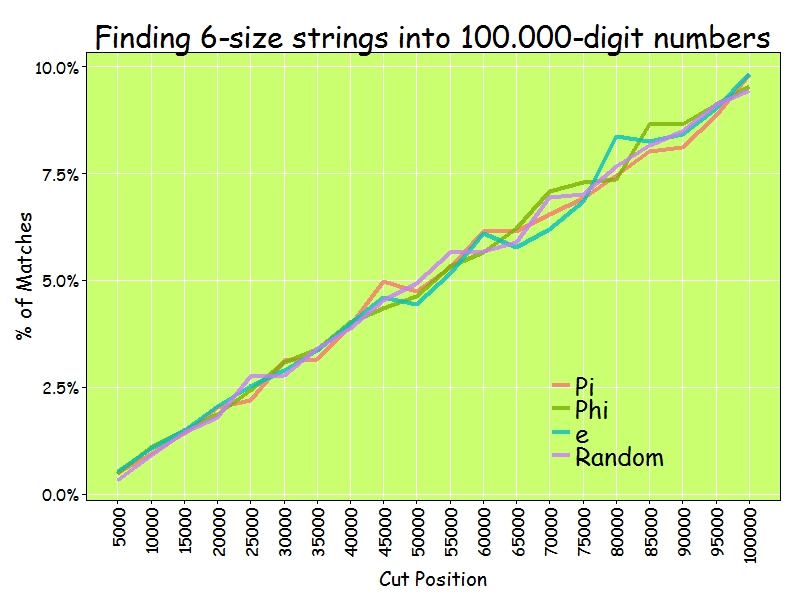
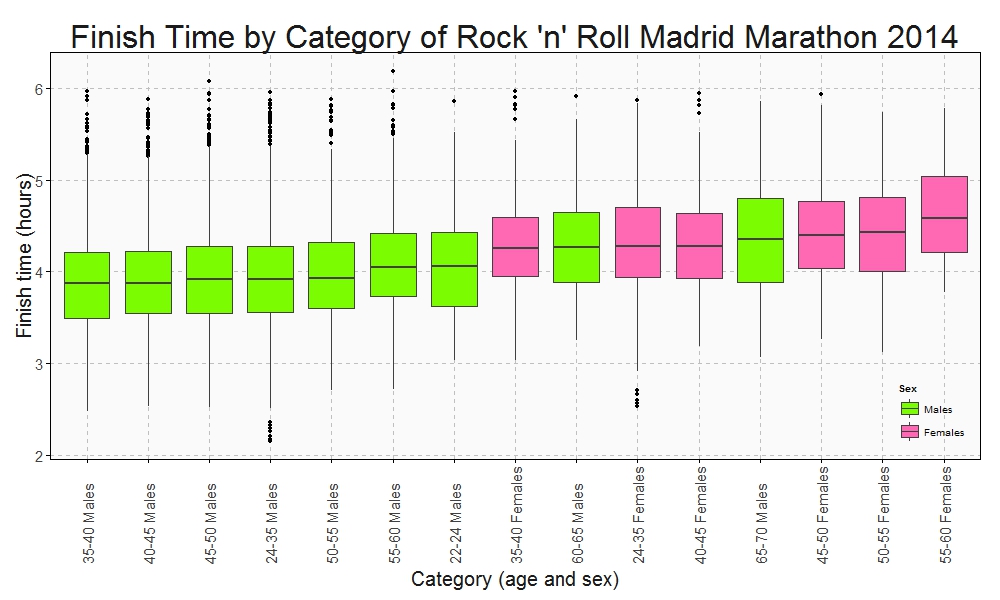
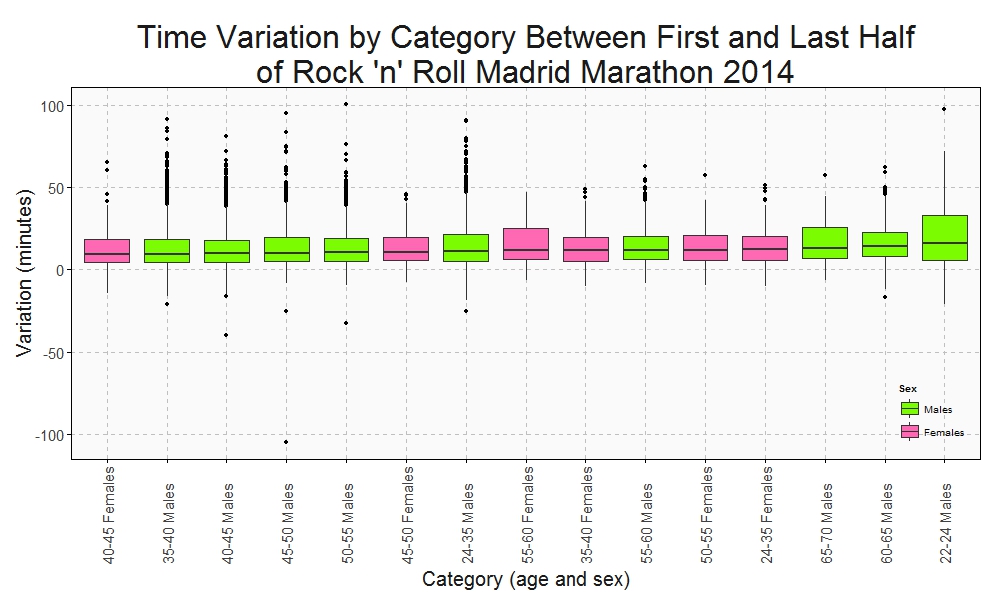
In the whole history of the world there is but one thing that money can not buy… to wit the wag of a dog’s tail (Josh Billings)
In this post I combine several things:
- Simple webscraping to read the list of companion dogs from Wikipedia. I love
rvestpackage to do these things - Google Trends queries to download the evolution of searchings of breeds during last 6 months. I use
gtrendsRpackage to do this and works quite well - A dinamic Highchart visualization using the awesome highcharter package
The experiment is based on a simple idea: what people search on the Internet is what people do. Can be Google Trends an useful tool to know which breed will become fashionable in the future? To be honest, I don’t really know but I will make my own bet.
What I have done is to extract last 6 months of Google trends of this list of companion breeds. After some simple text mining, I divide the set of names into 5-elements subsets because Google API doesn’t allow searchings with more than 5 items. The result of the query to Google trends is a normalized time series, meaning the 0 – 100 values are relative, not absolute, measures. This is done by taking all of the interest data for your keywords and dividing it by the highest point of interest for that date range. To make all 5-items of results comparable I always include King Charles Spaniel breed in all searchings (as a kind of undercover agent I will use to compare searching levels). The resulting number is my “Level” Y-Axis of the plot. I limit searchings to code=”0-66″ which is restrict results to Animals and pets category. Thanks, Philippe, for your help in this point. I also restrict rearchings To the United States of America.
There are several ways to obtain an aggregated trend indicator of a time series. My choice here was doing a short moving average order=2 to the resulting interest over time obtained from Google. The I divide the weekly variations by the smoothed time series. The trend indicator is the mean of these values. To obtains a robust indicator, I remove outliers of the original time series. This is my X-axis.
I discovered recently a wonderful package called highcharter which allows you to create incredibly cool dynamic visualizations. I love it and I could not resist to use it to do the previous plot with the look and feel of The Economist:
Inspired by Gartner’s Hype Cycle of Emerging Technologies I distinguish two sets of dog breeds:
- Plateau of Productivity Breeds (succesful breeds with very high level indicator and possitive trend): Golden Retriever, Pomeranian, Chihuahua, Collie and Shih Tzu.
- Innovation Trigger Breeds (promising dog breeds with very high trend indicator and low level): Mexican Hairless Dog, Keeshond, West Highland White Terrier and German Spitz.
And here comes my prediction. After analyzing the set Innovation Trigger Breeds, my bet is Keeshond will increase its popularity in the nearly future: don’t you think it is lovely?

Photo by Terri Brown – Flickr: IMG_4723, CC BY 2.0
Here you have the code:
library(gtrendsR)
library(rvest)
library(dplyr)
library(stringr)
library(forecast)
library(outliers)
library(highcharter)
library(ggplot2)
library(scales)
x="https://en.wikipedia.org/wiki/Companion_dog"
read_html(x) %>%
html_nodes("ul:nth-child(19)") %>%
html_text() %>%
strsplit(., "\n") %>%
unlist() -> breeds
breeds=iconv(breeds[breeds!= ""], "UTF-8")
usr <- "YOUR GOOGLE ACCOUNT"
psw <- "YOUR GOOGLE PASSWORD"
gconnect(usr, psw)
#Reference
ref="King Charles Spaniel"
#New set
breeds=setdiff(breeds, ref)
#Subsets. Do not worry about warning message
sub.breeds=split(breeds, 1:ceiling(length(breeds)/4))
results=list()
for (i in 1:length(sub.breeds))
{
res <- gtrends(unlist(union(ref, sub.breeds[i])),
start_date = Sys.Date()-180,
cat="0-66",
geo="US")
results[[i]]=res
}
trends=data.frame(name=character(0), level=numeric(0), trend=numeric(0))
for (i in 1:length(results))
{
df=results[[i]]$trend
lr=mean(results[[i]]$trend[,3]/results[[1]]$trend[,3])
for (j in 3:ncol(df))
{
s=rm.outlier(df[,j], fill = TRUE)
t=mean(diff(ma(s, order=2))/ma(s, order=2), na.rm = T)
l=mean(results[[i]]$trend[,j]/lr)
trends=rbind(data.frame(name=colnames(df)[j], level=l, trend=t), trends)
}
}
trends %>%
group_by(name) %>%
summarize(level=mean(level), trend=mean(trend*100)) %>%
filter(level>0 & trend > -10 & level<500) %>%
na.omit() %>%
mutate(name=str_replace_all(name, ".US","")) %>%
mutate(name=str_replace_all(name ,"[[:punct:]]"," ")) %>%
rename(
x = trend,
y = level
) -> trends
trends$y=(trends$y/max(trends$y))*100
#Dinamic chart as The Economist
highchart() %>%
hc_title(text = "The Hype Bubble Map for Dog Breeds") %>%
hc_subtitle(text = "According Last 6 Months of Google Searchings") %>%
hc_xAxis(title = list(text = "Trend"), labels = list(format = "{value}%")) %>%
hc_yAxis(title = list(text = "Level")) %>%
hc_add_theme(hc_theme_economist()) %>%
hc_add_series(data = list.parse3(trends), type = "bubble", showInLegend=FALSE, maxSize=40) %>%
hc_tooltip(formatter = JS("function(){
return ('<b>Trend: </b>' + Highcharts.numberFormat(this.x, 2)+'%' + '<br><b>Level: </b>' + Highcharts.numberFormat(this.y, 2) + '<br><b>Breed: </b>' + this.point.name)
}"))